Gated Slot Attention: Advancing Linear Attention Models for Efficient and Effective Language Processing

[ad_1]
Transformer models have revolutionized sequence modeling tasks, but their standard attention mechanism faces significant challenges when dealing with long sequences. The quadratic complexity of softmax-based standard attention hinders the efficient processing of extensive data in fields like video understanding and biological sequence modeling. While this isn’t a major concern for language modeling during training, it becomes problematic during inference. The Key-Value (KV) cache grows linearly with generation length, causing substantial memory burdens and throughput bottlenecks due to high I/O costs. These limitations have spurred researchers to explore alternative attention mechanisms that can maintain performance while improving efficiency, particularly for long-sequence tasks and during inference.
Linear attention and its gated variants have emerged as promising alternatives to softmax attention, demonstrating strong performance in language modeling and understanding tasks. These models can be reframed as RNNs during inference, achieving constant memory complexity and significantly enhancing efficiency. However, they face two key challenges. First, linear recurrent models struggle with tasks requiring in-context retrieval or learning, facing a fundamental recall-memory trade-off. Second, training these models from scratch on trillions of tokens remains prohibitively expensive, despite supporting hardware-efficient chunkwise training.
In this study, researchers from the School of Computer Science and Technology, Soochow University, Massachusetts Institute of Technology, University of California, Tencent AI Lab, LuxiTech, and University of Waterloo revisit the Attention with the Bounded-Memory Control (ABC) model, which retains the softmax operation, reducing discrepancies between standard and linear attention in training-finetuning scenarios. ABC enables more effective state utilization, requiring smaller state sizes for comparable performance. However, its potential has been overlooked due to mediocre language modeling performance and slow training speed. To address these limitations, the researchers reformulate ABC as two-pass linear attention linked via softmax, utilizing hardware-efficient chunkwise implementation for faster training.
Building on this foundation, they introduce Gated Slot Attention (GSA), a gated version of ABC that follows the trend of enhancing linear attention with gating mechanisms. GSA not only matches performance in language modeling and understanding tasks but also significantly outperforms other linear models in in-context recall-intensive tasks without requiring large state sizes. In the T2R finetuning setting, GSA demonstrates superior performance when finetuning Mistral-7B, surpassing large recurrent language models and outperforming other linear models and T2R methods. Notably, GSA achieves similar training speeds to GLA while offering improved inference speed due to its smaller state size.
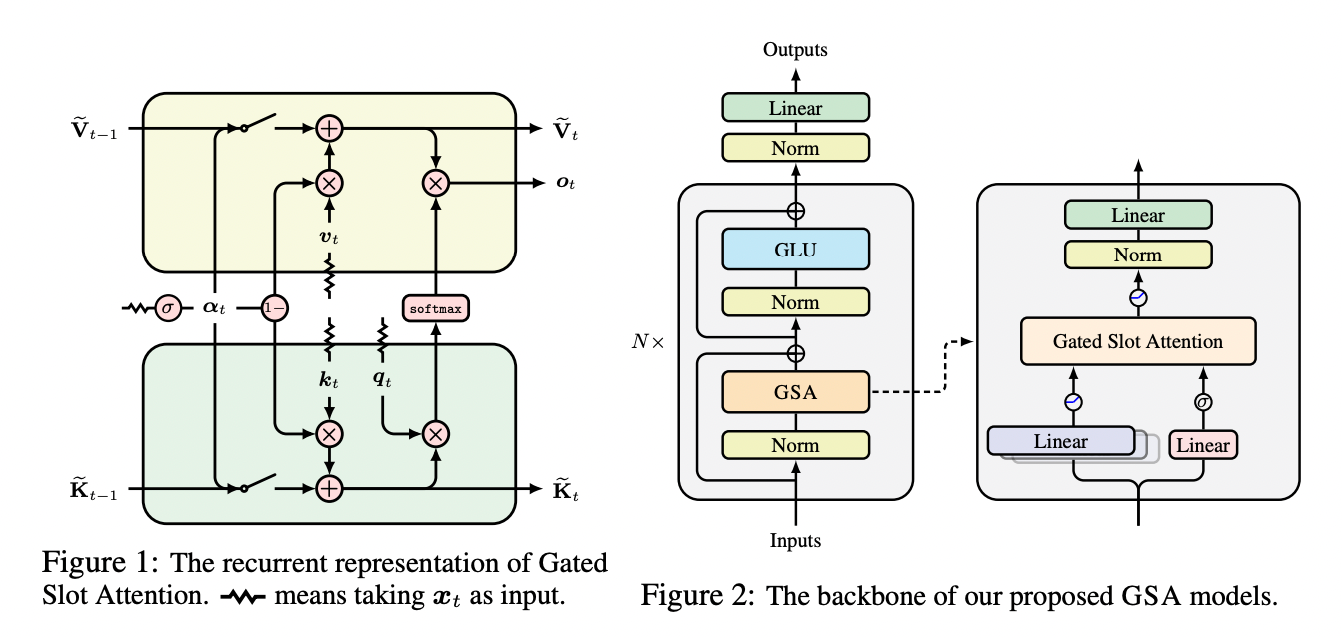
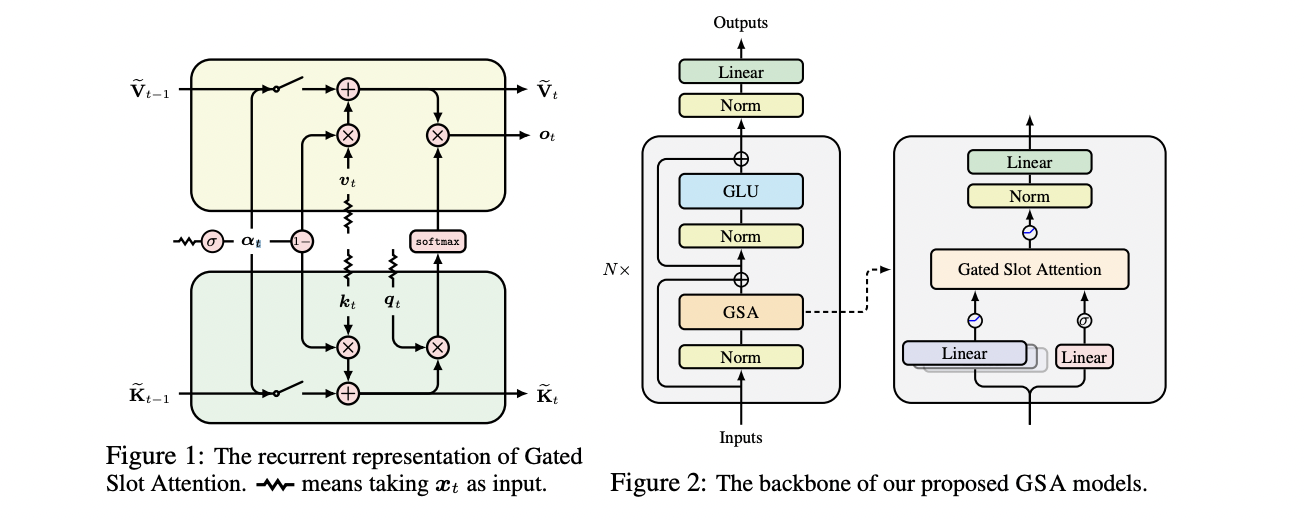
GSA addresses two key limitations of the ABC model: the lack of a forgetting mechanism and an unwarranted inductive bias favouring initial tokens. GSA incorporates a gating mechanism that enables forgetting of historical information and introduces a recency inductive bias, crucial for natural language processing.
The core of GSA is a gated RNN update rule for each memory slot, using a scalar data-dependent gating value. This can be represented in matrix form, reminiscent of HGRN2. GSA can be implemented as a two-pass Gated Linear Attention (GLA), allowing for hardware-efficient chunkwise training.
The GSA architecture consists of L blocks, each comprising a GSA token mixing layer and a Gated Linear Unit (GLU) channel mixing layer. It employs multi-head attention to capture different input aspects. For each head, the input undergoes linear transformations with Swish activation. A forget gate is obtained using a linear transformation followed by a sigmoid activation with a damping factor. The outputs are then processed through the GSA layer and combined to produce the final output. The model balances efficiency and effectiveness by carefully controlling parameter counts, typically setting the number of memory slots to 64 and using 4 attention heads.
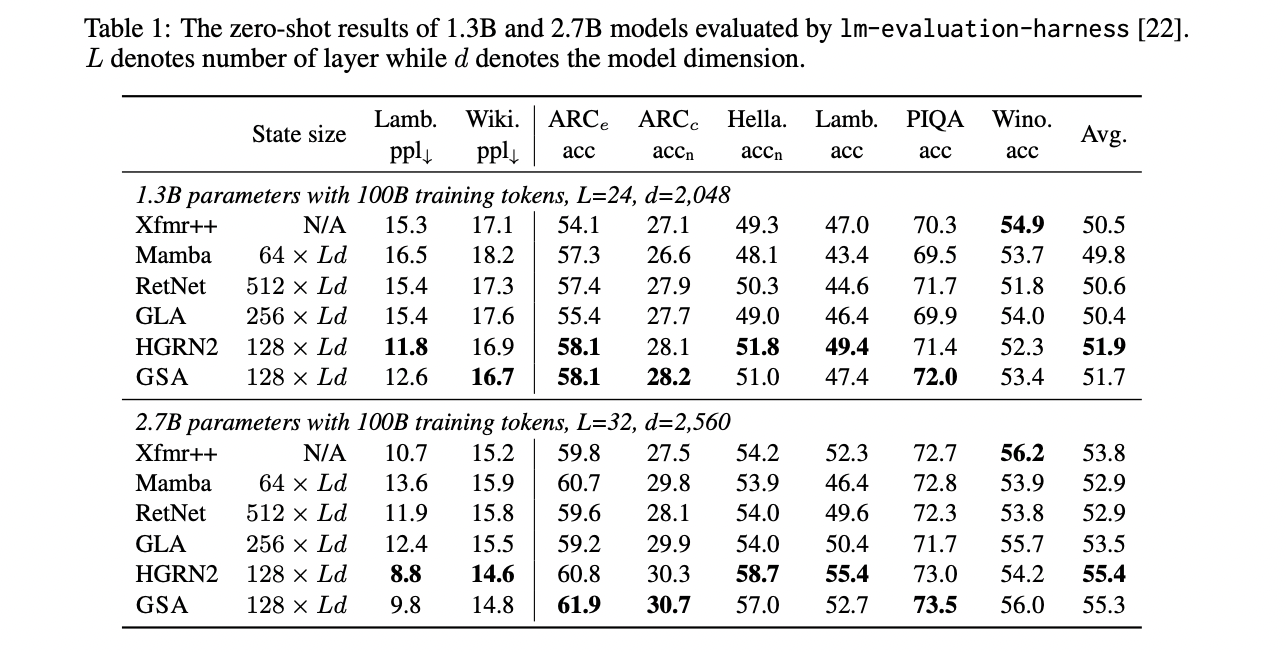
GSA demonstrates competitive performance in both language modeling and in-context recall-intensive tasks. In language modeling experiments on the Slimpajama corpus, GSA performs comparably to strong models like HGRN2 with equally sized hidden states, while outperforming GLA and RetNet even with smaller state sizes. For 1.3B and 2.7B parameter models, GSA achieves comparable or better results across various commonsense reasoning tasks, including ARC, Hellaswag, Lambada, PIQA, and Winograde.
In recall-intensive tasks, GSA shows significant improvements over other subquadratic models. On the synthetic Multi-Query Associative Recall (MQAR) task, GSA outperforms Mamba, GLA, RetNet, and HGRN2 across different model dimensions. For real-world recall-intensive tasks like FDA, SWDE, SQuAD, NQ, TriviaQA, and Drop, GSA consistently outperforms other subquadratic models, achieving an average performance closest to the Transformer (Xfmr++) baseline.

This study presents GSA that enhances the ABC model with a gating mechanism inspired by Gated Linear Attention. By framing GSA as a two-pass GLA, it utilizes hardware-efficient implementations for efficient training. GSA’s context-aware memory reading and forgetting mechanisms implicitly increase model capacity while maintaining a small state size, improving both training and inference efficiency. Extensive experiments demonstrate GSA’s advantages in in-context recall-intensive tasks and “finetuning pre-trained Transformers to RNNs” scenarios. This innovation bridges the gap between linear attention models and traditional Transformers, offering a promising direction for efficient, high-performance language modeling and understanding tasks.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
[ad_2]
Source link
